
【Java】既存処理をマルチスレッド化する
本稿はマルチスレッドを実装する上でとっても便利なクラスを紹介します。
個人ゲーム制作の実装で使うことはほぼ無いに等しいのですが、プログラムの規模が大きくなると処理速度を求められる場合が多々あります。
その他にもマルチスレッドを使わざる負えない場合にできるだけ安全な処理を実装したい場合や既存処理をマルチスレッド化する場合にも実装難易度を下げてくれます。
そんな時の実装手段の一つとして使えるクラスをサンプルを交えて紹介します。
簡単にマルチスレッド化できるThreadPoolExecutor
ThreadPoolExecutorとは複数のスレッドを保持させておき、特定の処理を実行する時に、ため込んだスレッドで処理を実行します。
そして処理が終わってもそのスレッドは削除されずにため込まれ、他の処理に使いまわされます。
下記イメージのように、処理一つにつきスレッドが一つ割り当てられます。処理数が多い場合は処理待機状態となります。
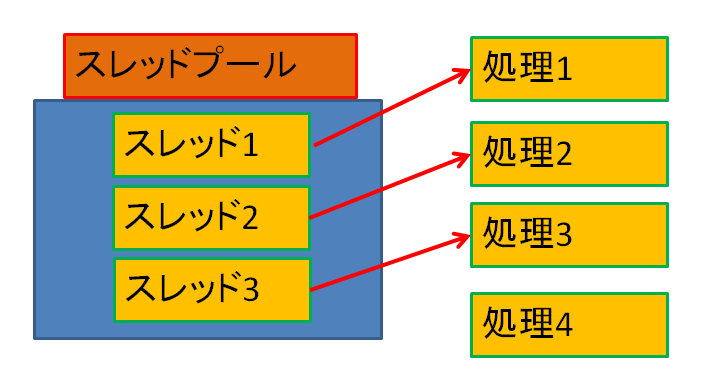
速く処理が終わったスレッドは終了せず待機中の処理を実行し始めます。この例ではスレッド3が速く終わったので、処理4を実行し始めます。
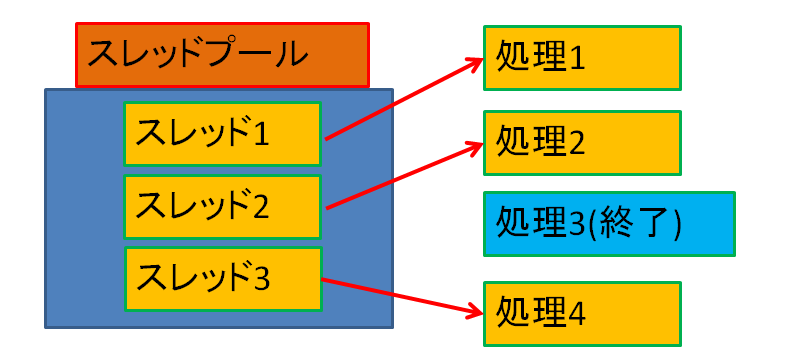
処理数が多い場合は次の処理が追加されまでスレッドを待機させておきます。この例ではスレッド1が待機状態になっており、新しい処理が追加されるとスレッド1で即座に実行されます。
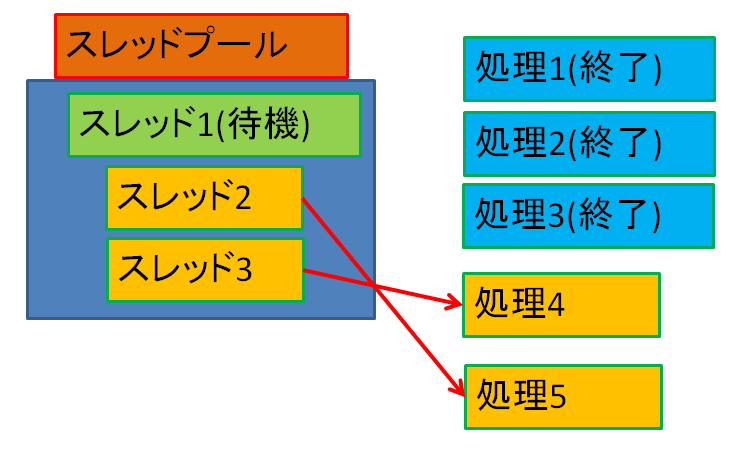
スレッドの起動にはコストがかかる為、複数の処理の分だけスレッドを起動するのでは、パフォーマンスを落としてしまいかねません。
そんなときにはこのクラスを利用することでより簡単に、スレッド数を制限したマルチスレッド化を実現することができます。
インスタンス化し、executeメソッドを呼び出すだけですぐに利用できます。
ThreadPoolExecutor th = new ThreadPoolExecutor( corePoolSize //溜めこむスレッド数 ,maximumPoolSize //起動できる最大スレッド数 ,keepAliveTime //臨時で起動したスレッド分を終了するまでの時間 ,unit //臨時で起動した分を終了するまでの時間の単位 ,workQueue //処理を表すオブジェクトをため込むリスト ); th.execute(処理);
見てみると引数は多いですが、それでも覚えておいて損はないはずです。
・corePoolSize
何スレッド保持させておくかを指定します
・maximumPoolSize
workQueueの形式により意味が変わります。LinkedBlockingQueueなら意味はなくなりますし、ArrayBlockingQueueなら処理数が溜まって容量制限に引っかかると溜めこむスレッド数を越えて一時的に新しいスレッドが起動されます。
・keepAliveTime
corePoolSizeを越えたスレッドが起動された場合に指定時間経過後にスレッドを終了させる。
・unit
keepAliveTimeの指定値が秒なのかミリ秒なのか等を指定する.
・workQueue
処理オブジェクトRunnableを保持するキュー形式のCollectionオブジェクト。通常はLinkedBlockingQueueでの実装が良いかと思われます。
・execute(処理)
処理を要求します。
・shutdown
既存タスクが終了してからThreadPoolExecutorを終了します。
・awaitTermination(期間,単位);
指定期間が経過するかThreadPoolExecutorが終了するまで現在のスレッドを待機させます。
それでは実際に特定の処理をマルチスレッド化してみるという例を出して使ってみましょう。
処理サンプルとして、1~500の数値を1ファイルずつに書き込むという単純な処理を作ってみます。
その後で処理をマルチスレッド化してみましょう。
実際の処理時間も計測してみます。
※multi_thread_testフォルダが自動作成され、中に大量のファイルが生成されますので、ご注意を!!
まずは普通の処理サンプルを作ります。
import java.io.BufferedWriter;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.StandardOpenOption;
public class Test {
public static void main(String[] args) {
try {
//時間計測用
long startTime = System.currentTimeMillis();
//テスト用ディレクトリの作成
Path directory = Paths.get("multi_thread_test");
Files.createDirectory(directory);
//500ファイル作る
for ( int i = 1;i <= 500;i++ ) {
//ファイル作成して数値を書き込み
try(BufferedWriter bw = Files.newBufferedWriter(directory.resolve(i+".txt"), StandardOpenOption.CREATE_NEW)){
bw.write(i+"");
}
}
//計測結果算出
System.out.println("処理時間:"+(System.currentTimeMillis() - startTime)+"ms");
} catch (Exception e) {
e.printStackTrace();
System.out.println("既にフォルダかファイルが作られているから処理できないよ!!");
}
}
}
処理時間:369ms
multi_thread_testにたくさんのファイルが生成されています。処理はうまくいっていますね。
それでは上記の処理をマルチスレッド化してみましょう。
import java.io.BufferedWriter;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.StandardOpenOption;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class Test {
public static void main(String[] args) {
try {
//時間計測用
long startTime = System.currentTimeMillis();
//テスト用ディレクトリの作成
Path directory = Paths.get("multi_thread_test");
Files.createDirectory(directory);
//4スレッドの並列処理を行う
ThreadPoolExecutor tpl = new ThreadPoolExecutor(4, 4, 0, TimeUnit.SECONDS, new LinkedBlockingQueue<>());
//500ファイル作る
for ( int i = 1;i <= 500;i++ ) {
//ファイル作成して数値を書き込み
tpl.execute(new Runnable() {
int n;
Runnable init(int n){
this.n = n;
return this;
}
public void run() {
try(BufferedWriter bw = Files.newBufferedWriter(directory.resolve(n+".txt"), StandardOpenOption.CREATE_NEW)){
bw.write(n+"");
} catch (IOException e) {
e.printStackTrace();
System.out.println("既にフォルダかファイルが作られているから処理できないよ!!");
}
}
}.init(i));
}
//終了要求
tpl.shutdown();
//終了まで待機。最大10000秒(秒数は適当です。)
tpl.awaitTermination(10000,TimeUnit.SECONDS);
//計測結果算出
System.out.println("処理時間:"+(System.currentTimeMillis() - startTime)+"ms");
} catch (Exception e) {
e.printStackTrace();
System.out.println("既にフォルダかファイルが作られているから処理できないよ!!");
}
}
}
処理時間:277ms
私の環境では平均して50ミリ~100ミリほど速くなりました。スペックの良い環境ほど速度は上がりそうです。数回試した結果マルチスレッドの最高速度は228ms、シングルスレッドの最高速度は327msでした。
この例では無駄な代入処理などをしているため若干マルチスレッドのほうが不利かなとも思いましたが速くなって良かったですw
もっと規模の大きい処理であれば大きな効果が期待できそうですね。まあその分マシンに負荷かかっちゃいますどね。
マルチスレッド化メソッド群Executors
ExecutorsクラスにはThreadPoolExecutorの使い勝手のいいstaticメソッドが多数存在します。
また、スケジューラ機能を有したオブジェクトを構築することもでき、非常に使いやすいです。以前にTimerの記事も書きましたが、どちらかといえばこちらの機能を私は好んで使用しております。
ではその便利な機能を一部見てみましょう。
指定スレッド数だけを使いまわして処理する
Executors.newFixedThreadPool(スレッド数)
を利用します。
指定値数のスレッドを起動しその数以内でスレッド使いまわして処理を実行するThreadPoolExecutorを構築します。
この稿の最初で紹介した500ファイル保存処理のThreadPoolExecutor構築部分をそのまま置き換えても同じ挙動になります。引数が減るのは嬉しいですね。
では置き換えたソースを見てみましょう。
import java.io.BufferedWriter;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.StandardOpenOption;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class Test {
public static void main(String[] args) {
try {
//時間計測用
long startTime = System.currentTimeMillis();
//テスト用ディレクトリの作成
Path directory = Paths.get("multi_thread_test");
Files.createDirectory(directory);
//4スレッドの並列処理を行う
ExecutorService es = Executors.newFixedThreadPool(4);
//500ファイル作る
for ( int i = 1;i <= 500;i++ ) {
//ファイル作成して数値を書き込み
es.execute(new Runnable() {
int n;
Runnable init(int n){
this.n = n;
return this;
}
public void run() {
try(BufferedWriter bw = Files.newBufferedWriter(directory.resolve(n+".txt"), StandardOpenOption.CREATE_NEW)){
bw.write(n+"");
} catch (IOException e) {
e.printStackTrace();
System.out.println("既にフォルダかファイルが作られているから処理できないよ!!");
}
}
}.init(i));
}
//終了要求
es.shutdown();
//終了まで待機。最大10000秒(秒数は適当です。)
es.awaitTermination(10000,TimeUnit.SECONDS);
//計測結果算出
System.out.println("処理時間:"+(System.currentTimeMillis() - startTime)+"ms");
} catch (Exception e) {
e.printStackTrace();
System.out.println("既にフォルダかファイルが作られているから処理できないよ!!");
}
}
}
処理時間:241ms
この例では4スレッドの並列処理を行っています。
キャッシュ式マルチスレッド機能
Executors.newCachedThreadPool()
を利用します。
必要であれば新しいスレッドを起動し、使いまわせるスレッドが残っていたらそれを使用して実行する使いやすい機能です。。。が、使いどころには注意が必要です。
この稿の最初で紹介した500ファイル保存処理の例で使用してしまうとスレッドを大量に起動していまいます。処理単位が同時にたくさんできる場合は使わないほうが無難ですね。
では500ファイル保存処理を置き換えて試してみましょう。
import java.io.BufferedWriter;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.StandardOpenOption;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class Test {
public static void main(String[] args) {
try {
//時間計測用
long startTime = System.currentTimeMillis();
//テスト用ディレクトリの作成
Path directory = Paths.get("multi_thread_test");
Files.createDirectory(directory);
//必要なら新しいスレッドを起動して並列処理をする
ExecutorService es = Executors.newCachedThreadPool();
//500ファイル作る
for ( int i = 1;i <= 500;i++ ) {
//ファイル作成して数値を書き込み
es.execute(new Runnable() {
int n;
Runnable init(int n){
this.n = n;
return this;
}
public void run() {
try(BufferedWriter bw = Files.newBufferedWriter(directory.resolve(n+".txt"), StandardOpenOption.CREATE_NEW)){
bw.write(n+"");
} catch (IOException e) {
e.printStackTrace();
System.out.println("既にフォルダかファイルが作られているから処理できないよ!!");
}
}
}.init(i));
}
//終了要求
es.shutdown();
//終了まで待機。最大10000秒(秒数は適当です。)
es.awaitTermination(10000,TimeUnit.SECONDS);
//計測結果算出
System.out.println("処理時間:"+(System.currentTimeMillis() - startTime)+"ms");
} catch (Exception e) {
e.printStackTrace();
System.out.println("既にフォルダかファイルが作られているから処理できないよ!!");
}
}
}
処理時間:320ms
流石にちょっと処理速度が落ちました。
スレッドをむやみやたらに起動するとこうなるということですね。
別スレッドで処理を順番に実行させる
Executors.newSingleThreadExecutor()
を利用します。
複数の処理単位を一つのスレッドを使いまわして処理させる時に便利です。
このシングルスレッドタイプのExecutorですが何の役に立つの?と思われるかもしれませんが、以外と便利です。
例えば、特定の処理を処理単位ごとに順番に実行したい場合などがあげられます。複数の処理をシングルスレッドで順番通りに実行させるのは、安全なプログラムを組むうえで重要なものだと思います。
では実際のサンプルを見てみましょうか。
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class Test {
public static void main(String[] args) throws InterruptedException {
//単一スレッドの使い回し
ExecutorService es = Executors.newSingleThreadExecutor();
es.execute(() -> print("あ"));
es.execute(() -> print("い"));
es.execute(() -> print("う"));
es.execute(() -> print("え"));
es.execute(() -> print("お"));
//終了要求
es.shutdown();
//終了まで待機。最大10000秒(秒数は適当です。)
es.awaitTermination(10000,TimeUnit.SECONDS);
}
public static void print(String s) {
try {
//1秒かかる処理
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(s);
}
}
あ
い
う
え
お
ちゃんと順番通りに実行されています。
別スレッドでスケジューラ機能を利用する
Executors.newSingleThreadScheduledExecutor()
を利用します。
返されたオブジェクトのscheduleメソッドやscheduleAtFixedRateメソッドを実行することで特定の時間後に実行させたり、定期実行させたりできます。
//1秒後に実行 schedule(Runnable, 1L, TimeUnit.SECONDS);
//1秒ごとに実行 scheduleAtFixedRate(Runnable, 0L, 1L, TimeUnit.SECONDS);
schedule系メソッドでの登録は複数可能であり、
scheduleAtFixedRate(Runnable, 0L, 1L, TimeUnit.SECONDS); scheduleAtFixedRate(Runnable, 0L, 2L, TimeUnit.SECONDS);
と連続で呼び出すと、1秒ごとのタスクと、2秒ごとのタスクをスケジューリングできます。とても便利です。
newSingleThreadScheduledExecutorで構築しているのでシングルスレッドタスクが実行されます。よって、特定の処理で遅延があれば以降の処理も遅延する可能性があります。
複数の同時実行を許容する場合は
Executors.newScheduledThreadPool(スレッド数)
を利用しましょう。
ではスケジューラのテストコードをご覧ください。
package com.nompor.app;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
public class Test {
static int cnt;
public static void main(String[] args) throws InterruptedException {
//単一スレッドのスケジューラ
ScheduledExecutorService ses = Executors.newSingleThreadScheduledExecutor();
//1秒ごとに処理を実行
ses.scheduleAtFixedRate(Test::exe, 0L, 1L, TimeUnit.SECONDS);
//5秒間メインスレッドの待機
Thread.sleep(5000);
//終了要求
ses.shutdown();
//終了まで待機。最大10000秒(秒数は適当です。)
ses.awaitTermination(10000,TimeUnit.SECONDS);
}
//タイマータスク
public static void exe() {
System.out.println(++cnt+"回目が実行されました。");
}
}
1回目が実行されました。
2回目が実行されました。
3回目が実行されました。
4回目が実行されました。
5回目が実行されました。
6回目が実行されました。